O projektu
Obecně
Náš projekt je zaměřen na využití Faginova top-k algoritmu a zároveň na možnost porovnat tento algoritmus s klasickým sekvenčním algoritmem. Faginův top-k algoritmus se využívá při vyhledávání v databázi produktů stejného typu dle atributů. Jeho výhoda spočívá v rychlejším vyhledávání dat, kde chceme vyhledat menší počet nejlepších výsledků. To, který produkt je nejlepší, je dáno nejvyšší normovanou hodnotou původní hodnoty daného atributu. Nakonec se vyberou a setřídí produkty dle agregační funkce, která musí být monotónní. V našem projektu jsme vybrali minimum, maximum a průměr.










Konkrétně
Projekt simuluje databázi notebooků, u kterých je uvedeno několik atributů (id, název, úhlopříčka, výdrž, CPU, RAM, HDD). Z těchto atributů je posledních 5 atributů vhodné pro vyhledávání. Dále lze vybrat jednu z agregačních funkcí, podle které získáme finální top-k produkty (minimum, maximum a průměr). V kolonce lze nastavit počet hledaných produktů, tedy top-k. A na závěr lze vybrat jeden z algoritmů vyhledávání a to Fagin top-k algoritmus anebo sekvenční vyhledávání, čímž si můžeme snadno porovnat výsledky pro stejné dotazy. Hned po vyhledání se totiž objeví alert-okno s délkou běhu výpočtu v milisekundách.
Způsob řešení
Řešili jsme problém podle nastudovaných přednášek, tedy podle základních principů Faginova algoritmu. V první fázi jsme vytvořili pseudonáhodný generátor insert skriptů notebooků, tím jsme vytvořili celkem obsáhlou databázi. Poté jsme vytvořili jednoduché webové rozhraní. Druhý krok již bylo samotné programování, tvorba normalizačního skriptu, který stáhl informace z databáze a vytvořil další tabulky s normalizovanými hodnotami. V poslední fázi jsme naprogramovali samotný Faginův algoritmus.
Implementace
Z počátku jsme chtěli implementovat algoritmus plně na klientské straně a zasílat serveru požadavky na databázi, ale brzy jsme usoudili, že je to špatný nápad, jelikož neustálá práce s databází a opětovné zasílání odpovědí by byla velmi neefektivní. Proto veškeré výpočty probíhají na straně serveru pomocí PHP a výsledné produkty se zasílají pomocí jQuery na klienta a vykreslí pomocí javascriptu/DOM.
Databáze je vytvořená pomocí aplikace phpMyAdmin, kde máme tabulku pro produkty s reálnými hodnotami a následně tabulky s normovanými hodnotami pro každý atribut.
Příprava
Po prvním spuštění aplikace se načtou produkty z databáze a následně se vypočítávají normované hodnoty, které se do databáze ukládají. Pro výpočet normovaných hodnot jsme vytvořili vzorec:
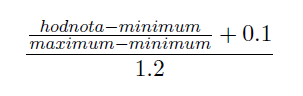
Algoritmus
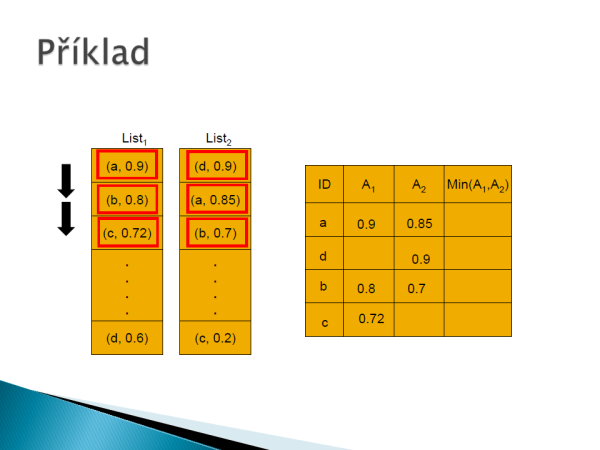
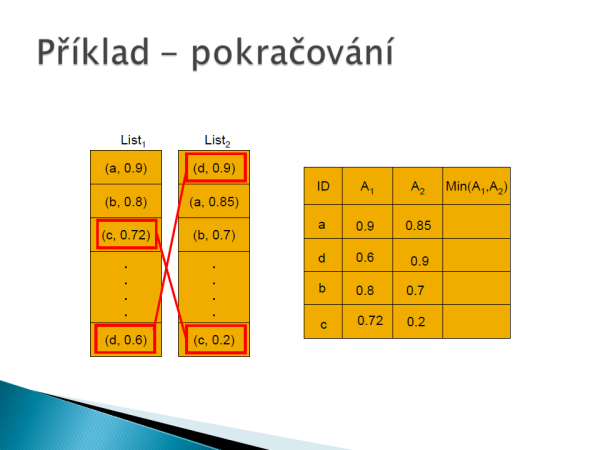
Vytvoříme jedno velké pole, které má rozměr: počet atributů x počet produktů. Naplníme pole normovanými hodnotami sestupně pomocí dotazu ORDER BY VALUE DESC.
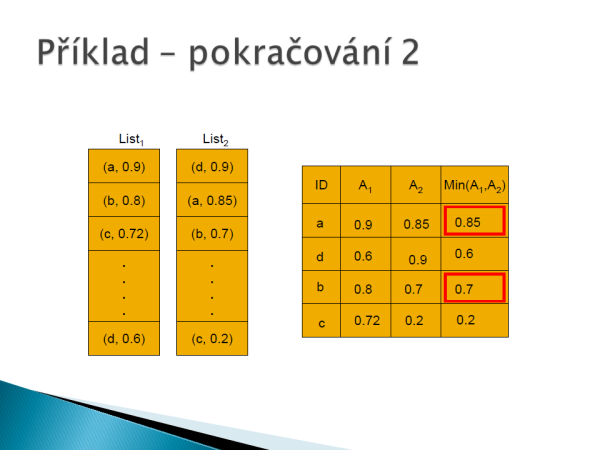
Následně vytvoříme další pole, které plníme do té doby, dokud není plných k řádků. Jakmile máme řádky plné, tak vyskočíme z cyklu a doplníme prázdné hodnoty v poli a vypočítáme naši finální hodnotu dle agregační funkce, která je zvolená.
Výsledné hodnoty seřadíme sestupně a vybereme top-k produktů, které vrátíme zpět klientovi a vykreslíme.
Experimentální sekce
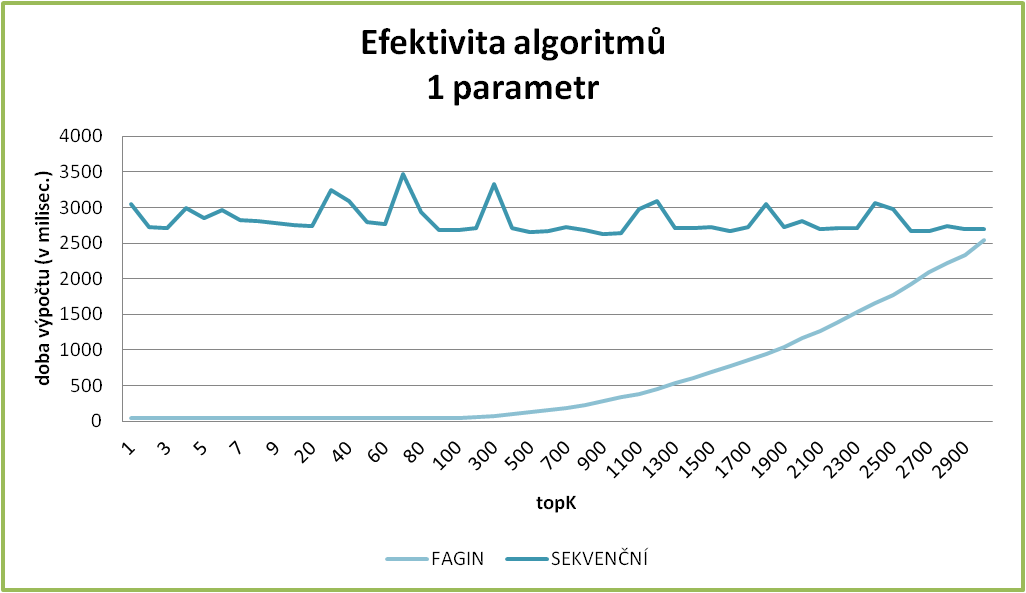
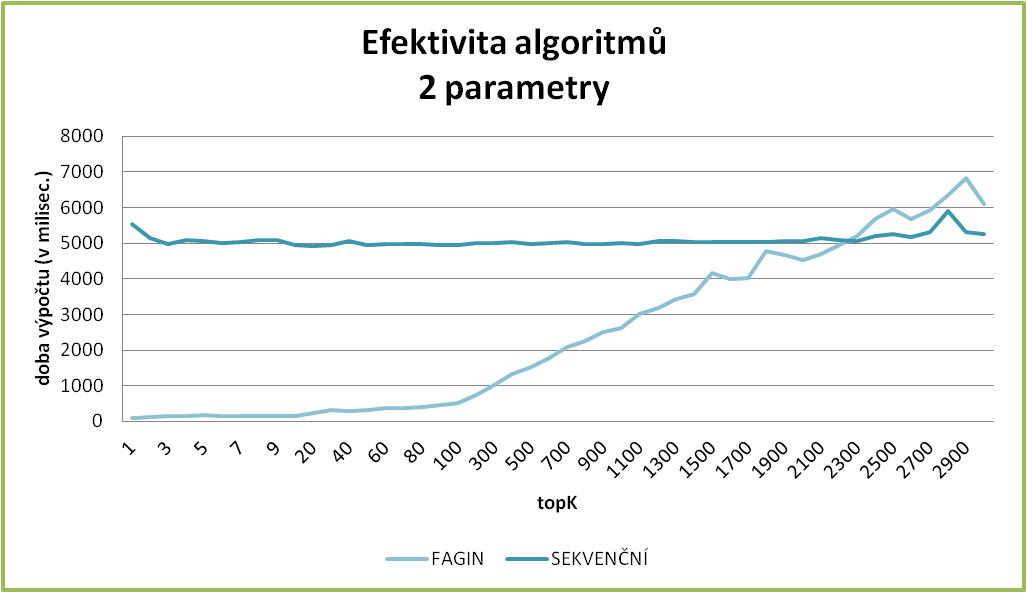
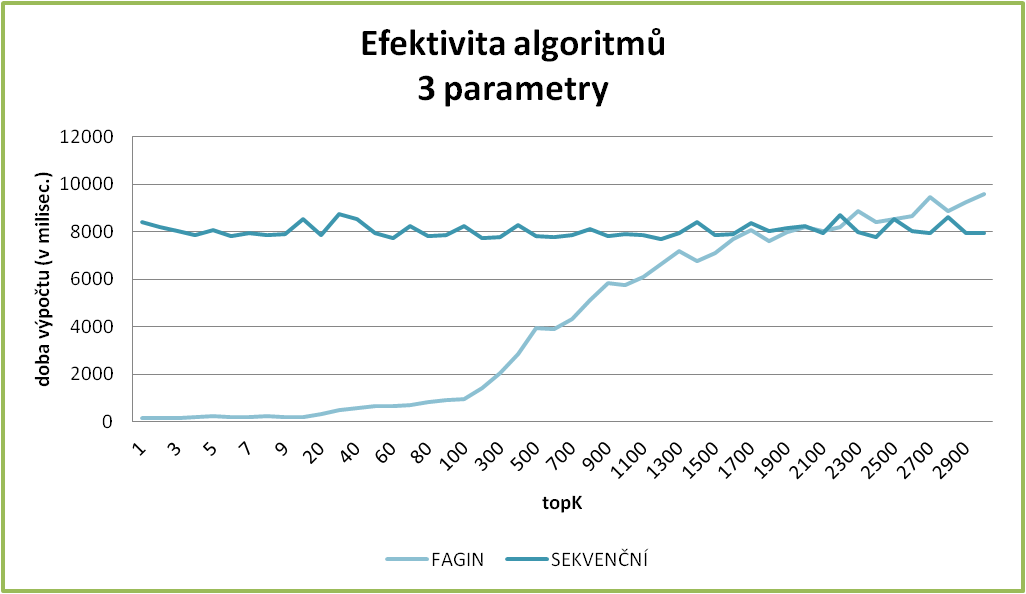
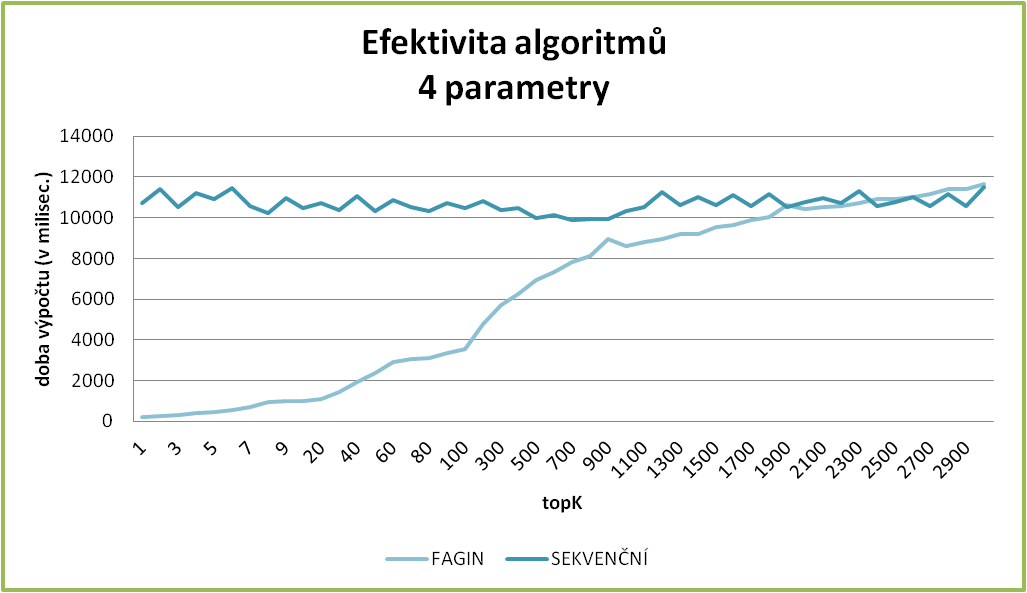
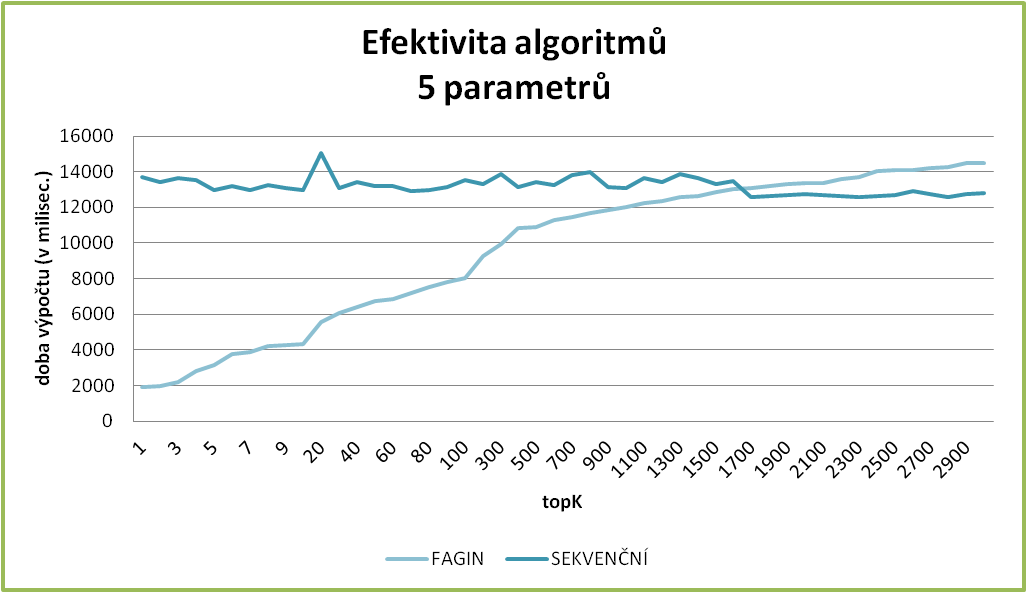
Zde uvádíme několik grafů, které krásně prezentují závislosti. Jednak je zde dobře vidět, jak se mění rozdíl v rychlostech vyhledávání mezi Faginovým a sekvenčním algoritmem, kdy pro malé k je Faginův algoritmus mnohem rychlejší, zato při k blížícím se k počtu záznamů v tabulce, se Faginův algoritmus blíží k rychlosti sekvenčního vyhledávání, až je nakonec i pomalejší (což zapříčiňuje náročnější režie).
Stejně tak můžeme sledovat, jak se prodlužuje čas vyhledávání, když hledáme pro stejné k položky s více zvolenými atributy.